
探索树结构与堆的基本特性
树
树是一种在计算机科学和数学领域中常见的数据结构,它由节点(nodes)和边(edges)组成。树的结构呈现出分层的层次关系,其中一个节点称为树根(root),它没有父节点,而其他节点则有一个父节点和零个或多个子节点。
树是一种递归定义的数据结构。除根节点外,其余节点被划分为多个互不相交的子树,每个子树都是一棵树,也满足树的定义。每个子树的根节点有且只有一个前驱,可以有零个或多个后继节点。这种递归的定义使得树能够灵活地表示层次结构,并在每个子树中重复应用相同的结构。

概念
-
节点的度:
- 一个节点含有的子树的个数称为该节点的度。
-
叶节点或终端节点:
- 度为0的节点称为叶节点,也称为终端节点。
-
非终端节点或分支节点:
- 度不为0的节点称为非终端节点或分支节点。
-
双亲节点或父节点:
- 若一个节点含有子节点,则这个节点称为其子节点的父节点。
-
孩子节点或子节点:
- 一个节点含有的子树的根节点称为该节点的子节点。
-
兄弟节点:
- 具有相同父节点的节点互称为兄弟节点。
-
树的度:
- 一棵树中,最大的节点的度称为树的度。
-
节点的层次:
- 从根开始定义起,根为第1层,根的子节点为第2层,以此类推。
-
树的高度或深度:
- 树中节点的最大层次称为树的高度或深度。
-
堂兄弟节点:
- 双亲在同一层的节点互为堂兄弟。
-
节点的祖先:
- 从根到该节点所经分支上的所有节点。
-
子孙:
- 以某节点为根的子树中任一节点都称为该节点的子孙。
-
森林:
- 由m(m>0)棵互不相交的树的集合称为森林。
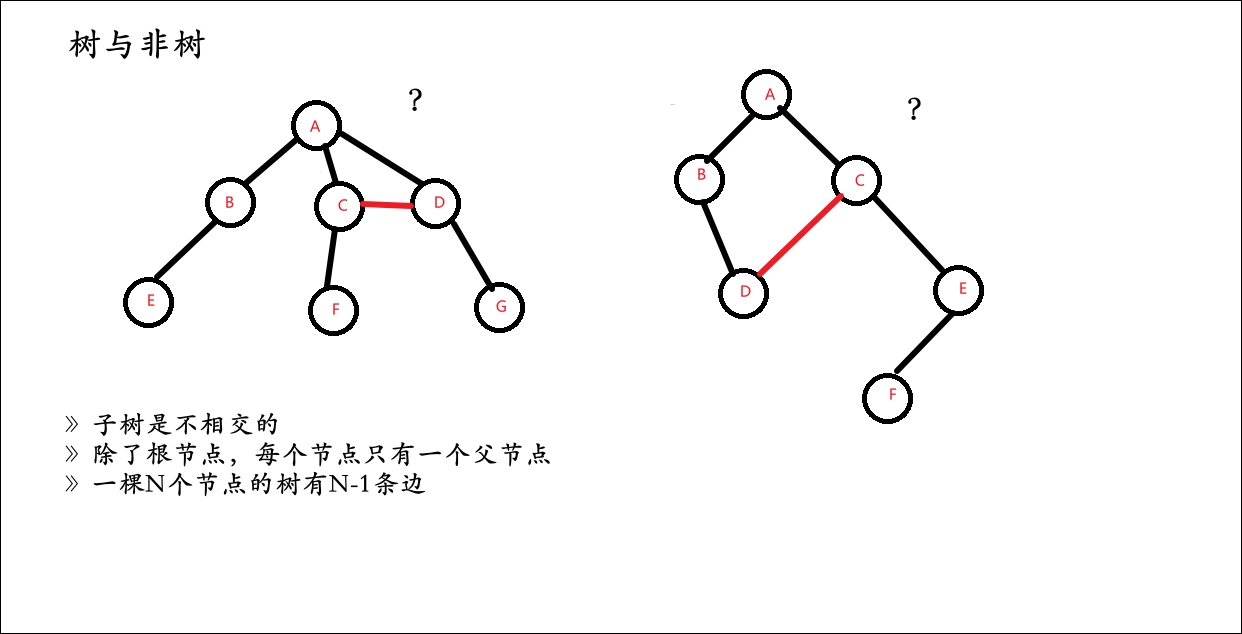
注意:树形结构中,子树之间不能有交集,否则就不是树形结构。
应用
-
文件系统:
- 文件系统通常使用树的结构来组织文件和目录。每个目录可以包含文件和子目录,形成一个层次结构,便于快速定位和管理文件。

-
数据库:
- 在数据库中,树结构通常用于构建索引。二叉搜索树(BST)或其变体被广泛应用于数据库索引,以提高数据检索的效率。
-
组织结构和层次关系:
- 树结构可以用于表示组织机构中的层次关系,例如公司的组织结构图。
-
电子游戏中的场景图:
- 游戏引擎使用树结构来表示游戏场景中的对象,以便更方便地管理和渲染游戏中的元素。

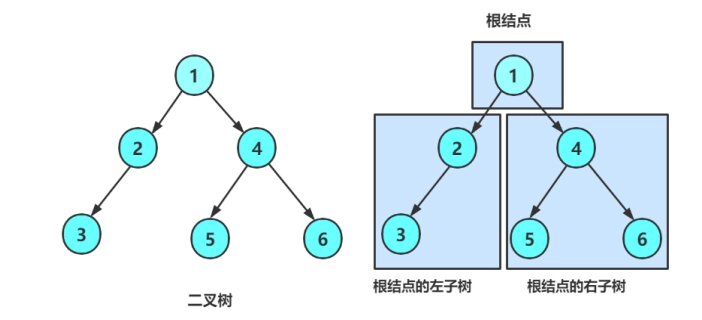
二叉树
二叉树(Binary Tree)是一种树形结构,其中每个节点最多有两个子节点,分别称为左子节点和右子节点。
概念
- 结构:
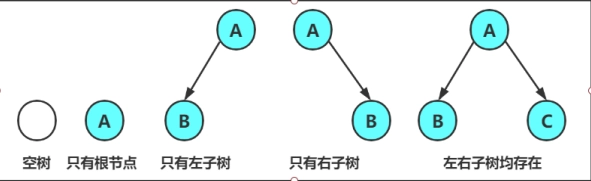
- 二叉树可能为空(没有节点)。
- 或者包含一个根节点,以及分别称为左子树和右子树的两个二叉树(左右子树也可能为空)。
- 结点度的限制:
- 二叉树不存在度大于2的节点,每个节点最多有两个子节点。
- 子树的有序性:
- 二叉树的子树有左右之分,左子树和右子树的次序不能颠倒,即左子树始终在右子树的前面。
注意:对于任意的二叉树都是由以下几种情况复合而成的
特殊二叉树
-
满二叉树(Full Binary Tree):
- 在满二叉树中,每个节点要么是叶子节点,要么具有两个子节点。每一层都是完全填充的。
-
完全二叉树(Complete Binary Tree):
- 完全二叉树是指除了最后一层外,其他各层的节点都是满的,而且最后一层的节点从左到右依次填充。这种树结构在数组中的表示非常有效。
-
二叉搜索树(Binary Search Tree,BST):
- 在二叉搜索树中,每个节点的值大于其左子树中的任何节点的值,且小于其右子树中的任何节点的值。这种性质使得查找、插入和删除等操作更加高效。
-
平衡二叉树(Balanced Binary Tree):
- 平衡二叉树是一种高度平衡的二叉树,确保左右子树的高度差不超过某个固定的值。常见的平衡二叉树包括 AVL 树和红黑树。
-
二叉堆(Binary Heap):
- 二叉堆是一种特殊的完全二叉树,它分为最小堆和最大堆两种。在最小堆中,每个节点的值都小于或等于其子节点的值;在最大堆中,每个节点的值都大于或等于其子节点的值。
-
霍夫曼树(Huffman Tree):
- 霍夫曼树是用于数据压缩的一种特殊二叉树,其中频率较高的字符在树中的深度较小,频率较低的字符在树中的深度较大。
这些特殊二叉树在不同的应用场景中有着不同的优势,根据具体需求选择适合的二叉树结构可以提高算法的效率。
性质

存储结构
- 链式存储结构:
- 每个节点包含数据域和两个指针域,分别指向左子树和右子树。
- 节点的定义可以是类似于下面的结构体(在编程语言中的表示):
1 | struct TreeNode { |
- 链式存储更直观,适用于不规则的二叉树。
- 顺序存储结构:
- 使用数组来表示二叉树,按照层次遍历的顺序存储节点。
- 如果某个节点的序号是i,其左孩子的序号为2i+1,右孩子的序号为2i+2。
- 如果某个节点的序号为i,其双亲的序号为(i-1)/2。
- 顺序存储结构节省空间,适用于完全二叉树,但不适用于不规则的二叉树。
1 | 数组表示的二叉树: [D, B, E, A, C, F, G] |
选择合适的存储结构取决于具体的应用场景和对操作的需求。链式存储适用于树结构不规则的情况,而顺序存储适用于满足完全二叉树条件的情况。
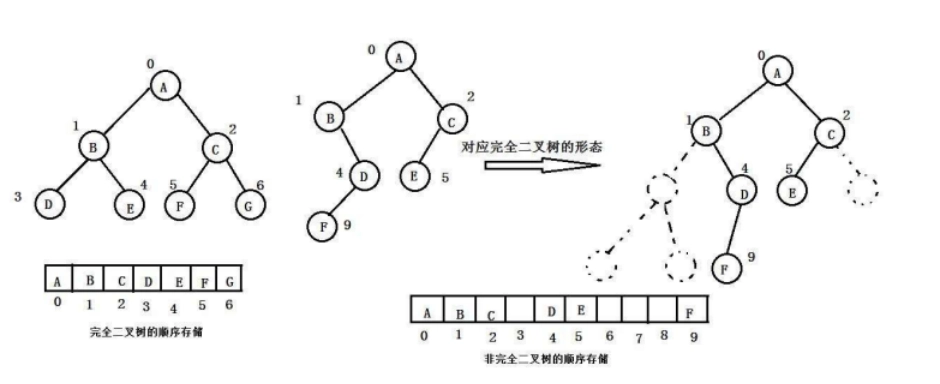
顺序存储结构在不规则的二叉树中存在一些问题,主要涉及到浪费空间和难以确定子节点位置的情况:
问题1: 浪费空间
- 对于不规则的二叉树,有些节点可能没有左孩子或右孩子,但在数组中需要保留对应的位置。这样会导致大量的空间浪费,因为存储的数组大小通常需要按照完全二叉树的形式来预分配,即便实际上树的结构并不规则。
问题2: 难以确定子节点位置
- 在顺序存储结构中,通过节点的序号来确定其子节点和双亲节点的位置。但在不规则的二叉树中,节点的左右子树可能不满足2i+1和2i+2的关系,这使得确定子节点的位置变得复杂。
- 不规则的二叉树可能有空缺的位置,而这些空缺位置可能被错误地解释为节点缺失,导致无法正确获取节点的子节点信息。
综合这两点,顺序存储结构在不规则的二叉树中并不是一个有效的选择,链式存储结构更适合表示不规则结构的二叉树,因为它可以更灵活地动态分配内存,而不需要提前规定数组大小。链式存储结构通过指针的连接能够更自由地表示任意形状的二叉树,而不受固定数组大小的限制。
顺序结构
普通的二叉树在使用数组存储时确实容易出现大量的空间浪费,因为普通二叉树的结构可能比较不规则,节点数量不一定充分利用数组的连续存储特性。相反,完全二叉树更适合使用顺序结构来存储,因为它具有规则的结构,可以充分利用数组,减少空间浪费。
在实际应用中,堆这种二叉树结构通常使用顺序结构的数组来存储。需要注意的是,这里的堆指的是数据结构中的堆,用于实现优先队列等操作,而不是操作系统虚拟进程地址空间中的堆,后者是用于动态分配内存的一块区域。
堆
堆是一种特殊的二叉树数据结构,用于实现一些高效的操作,主要包括优先队列的实现。堆分为最大堆(Max Heap)和最小堆(Min Heap)两种类型,具体的性质如下:
- 最大堆(Max Heap):
- 对于任意节点 i,其值大于或等于其子节点的值。
- 根节点(堆顶元素)是整个堆中的最大值。
- 最小堆(Min Heap):
- 对于任意节点 i,其值小于或等于其子节点的值。
- 根节点(堆顶元素)是整个堆中的最小值。
堆的实现通常使用数组来表示,数组中的元素按照堆的结构从上到下、从左到右进行排列。通过这种方式,可以通过数组的索引关系快速定位节点的父节点和子节点,从而实现高效的操作。
基本性质
- 堆是一棵完全二叉树,除了最底层,其他层的节点都是满的,并且最底层的节点都集中在左侧。
- 堆中的每个节点的值都满足堆的性质,即最大堆或最小堆的性质。
操作
- 插入操作: 将新元素插入堆的最后一个位置,然后通过上移操作(Heapify Up)调整堆,以满足堆的性质。
- 删除操作: 删除堆顶元素,将堆的最后一个元素移动到堆顶,然后通过下移操作(Heapify Down)调整堆,以满足堆的性质。
1 | // 堆的数组表示 |
通过这种数组表示,可以通过一些简单的数学关系快速找到节点的父节点和子节点。例如,对于节点 i:
- 其父节点的索引为
(i-1)/2。 - 其左子节点的索引为
2i+1。 - 其右子节点的索引为
2i+2。
这些关系使得堆的操作能够在 O(log n) 的时间复杂度内完成,其中 n 是堆中元素的个数。
实现
在堆数据结构中,向下调整(Heapify Down)和向上调整(Heapify Up)是用于维护堆性质的两个重要操作。这两种操作通常在插入和删除元素时使用,确保堆仍然是一个有效的最大堆或最小堆。
向下调整(Heapify Down)算法:
向下调整的目的是将一个不满足堆性质的子树调整为满足堆性质的子树。具体步骤如下:
-
比较当前节点与其子节点: 检查当前节点与其左右孩子节点的大小关系,找到最大值或最小值的孩子节点。
-
交换操作: 如果最大值或最小值的孩子节点的值大于(最大堆)或小于(最小堆)当前节点的值,交换它们的值。
-
迭代调整: 迭代地对交换后的子树进行向下调整,确保整个树仍然满足堆性质。
向上调整(Heapify Up)算法:
向上调整的目的是将一个不满足堆性质的节点调整为满足堆性质的节点。具体步骤如下:
-
比较当前节点与其父节点: 检查当前节点与其父节点的大小关系。
-
交换操作: 如果当前节点的值大于(最大堆)或小于(最小堆)其父节点的值,交换它们的值。
-
迭代调整: 迭代地对交换后的父节点进行向上调整,确保整个树仍然满足堆性质。
示例代码:
向下调整
1 | void heapifyDown(int heap[], int n, int i) { |
向上调整
1 | void heapifyUp(int heap[], int i) { |
